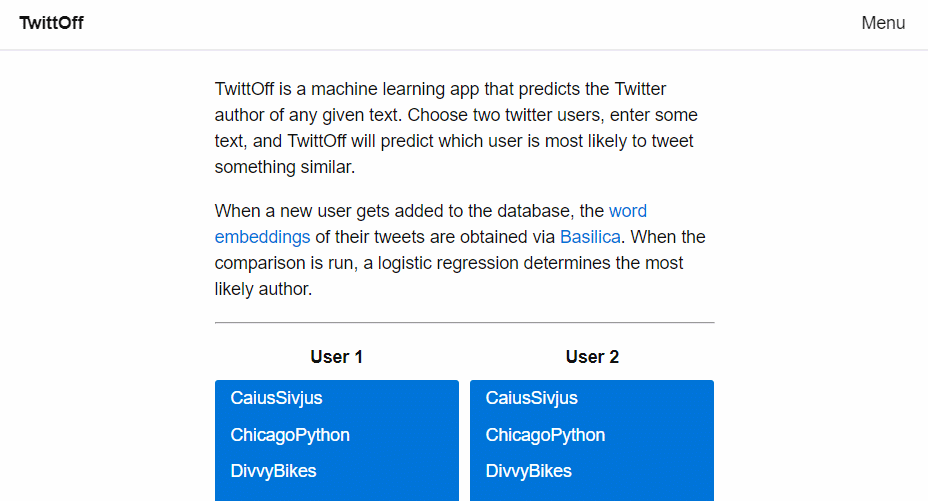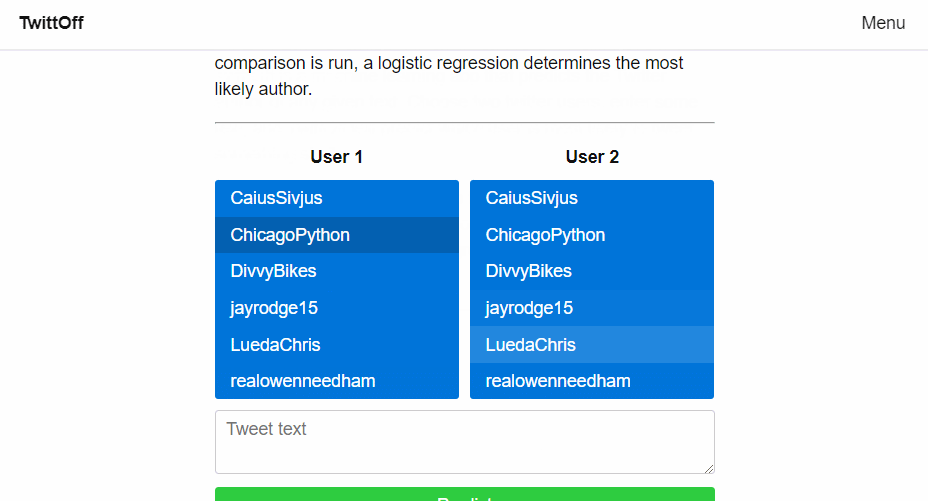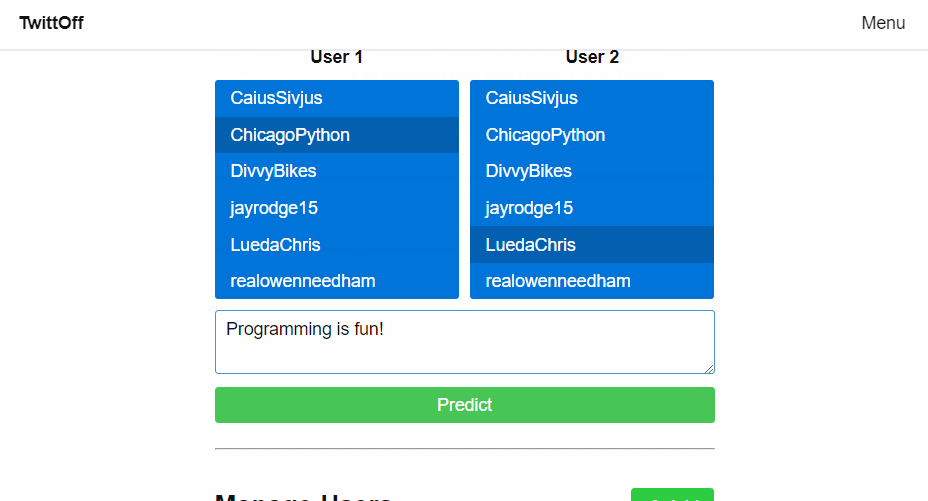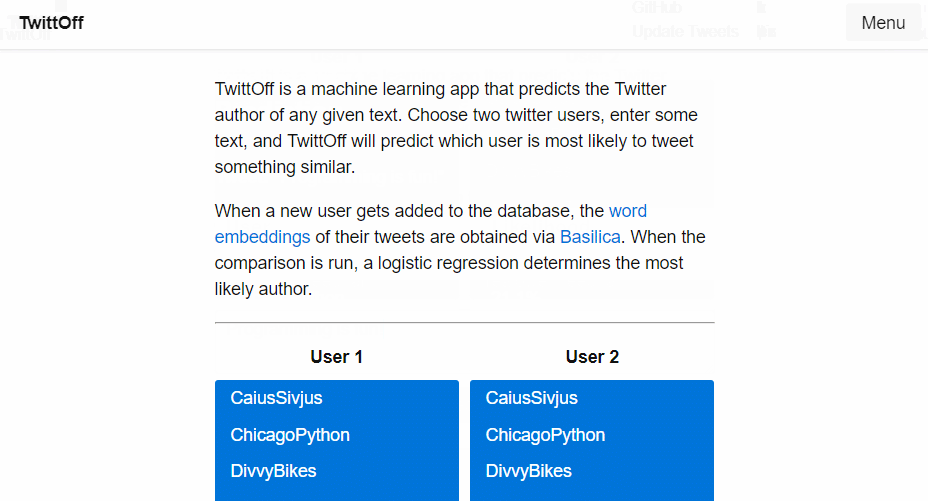
About

I help organizations provide better products and programs with code. My work involves end-to-end data streaming, transformation, and presentation for action.
My tools are Terraform, Airflow, Snowflake, and Python.
I help organizations provide better products and programs with code. My work involves end-to-end data streaming, transformation, and presentation for action.
My tools are Terraform, Airflow, Snowflake, and Python.
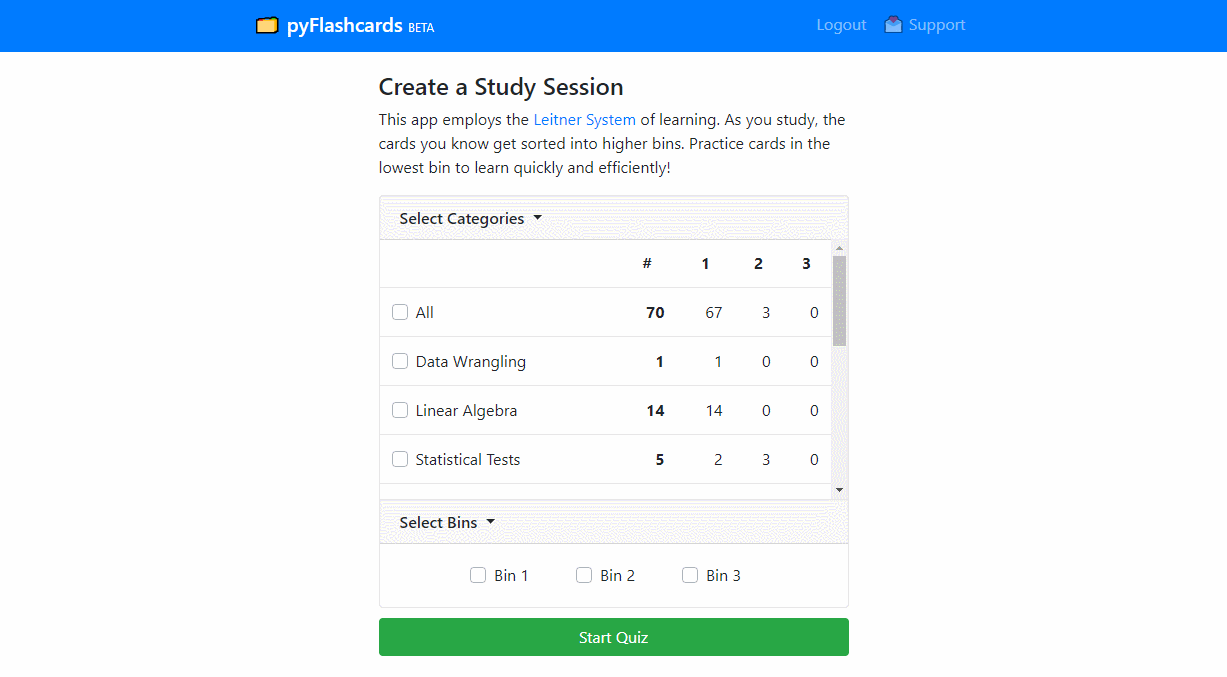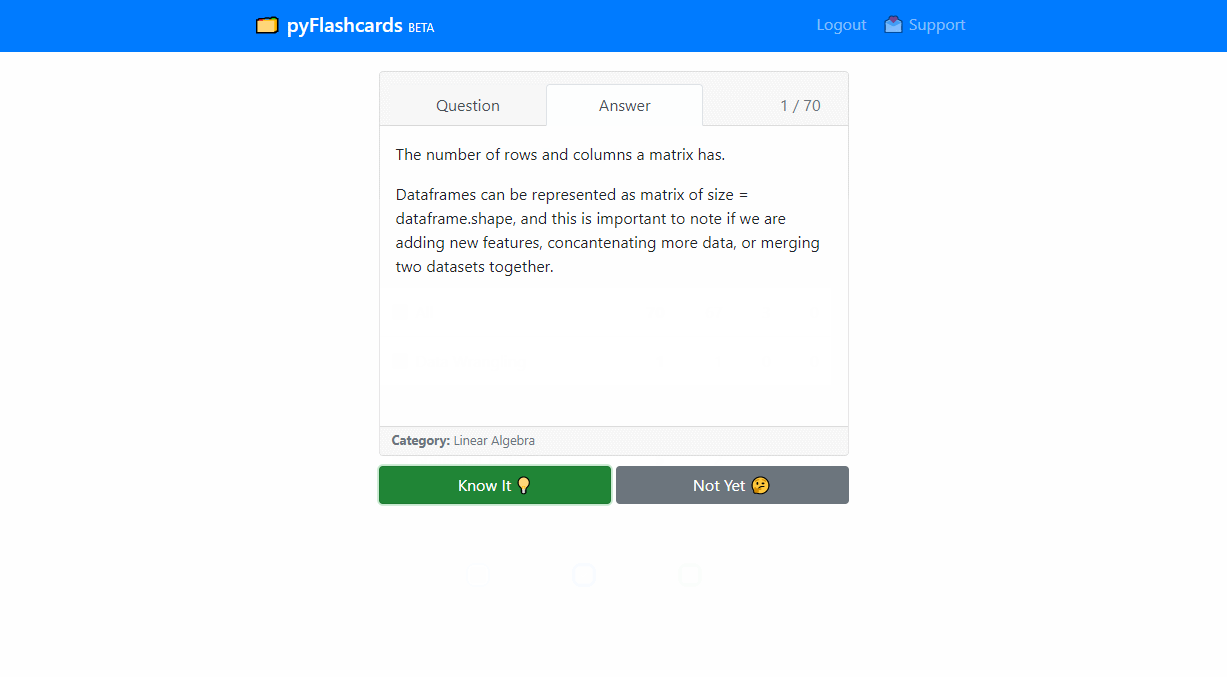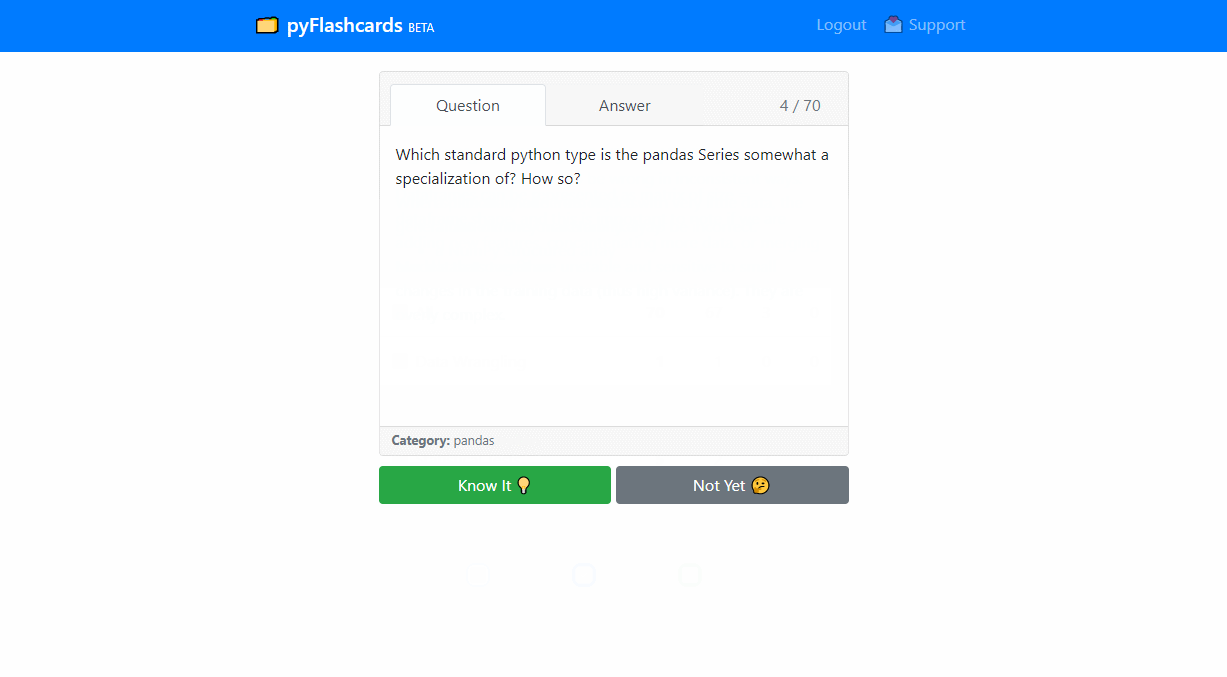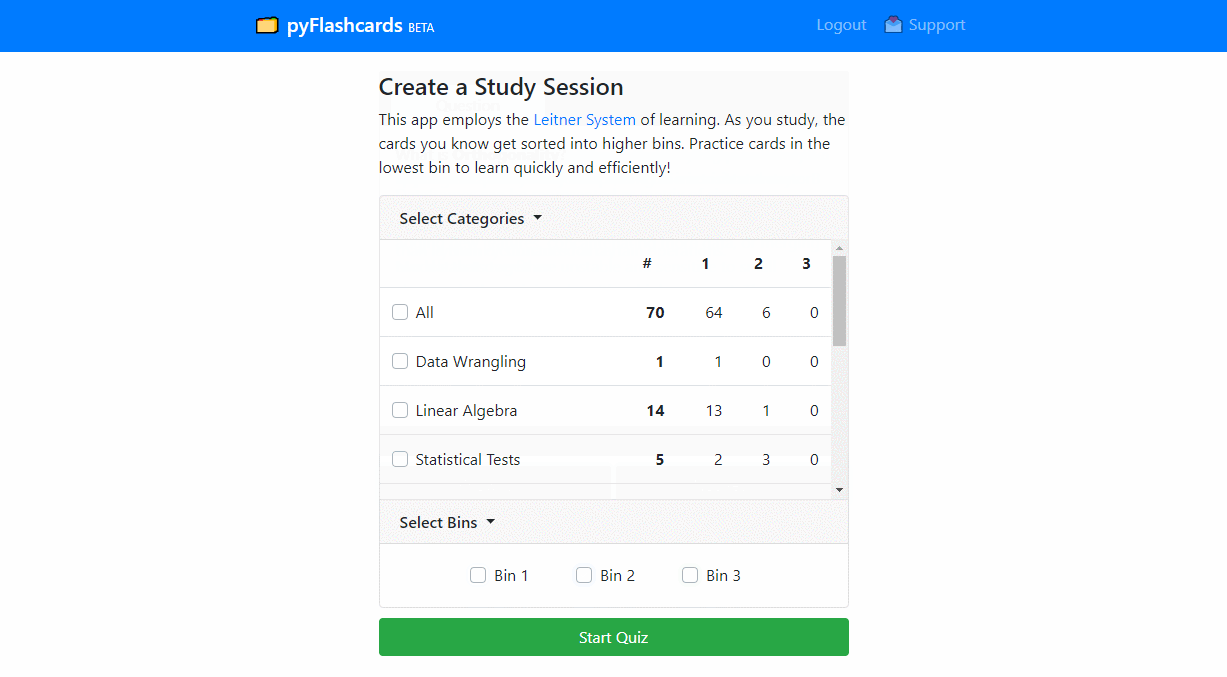
Learn and remember data science better using the Leitner System of learning. As you study, the cards you know get sorted into higher bins. Practicing cards in lower bins lead to quick and efficient learning. As users provide data, a machine learning model will recommend quiz sets and learning intervals.
View App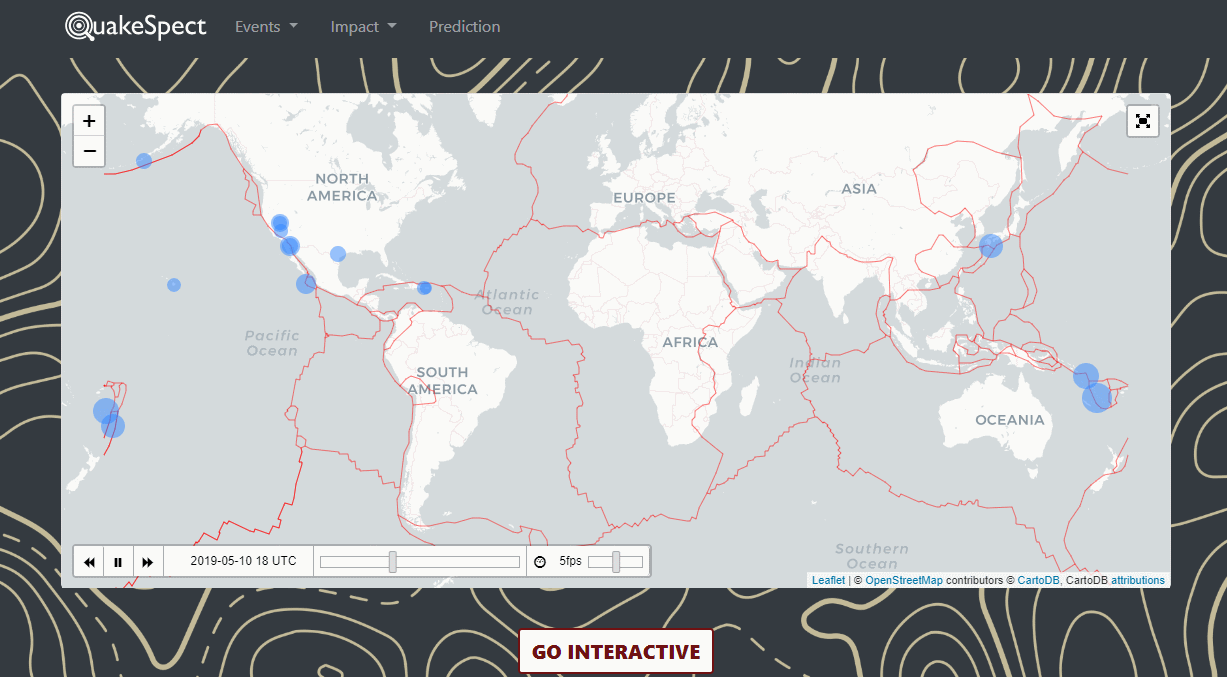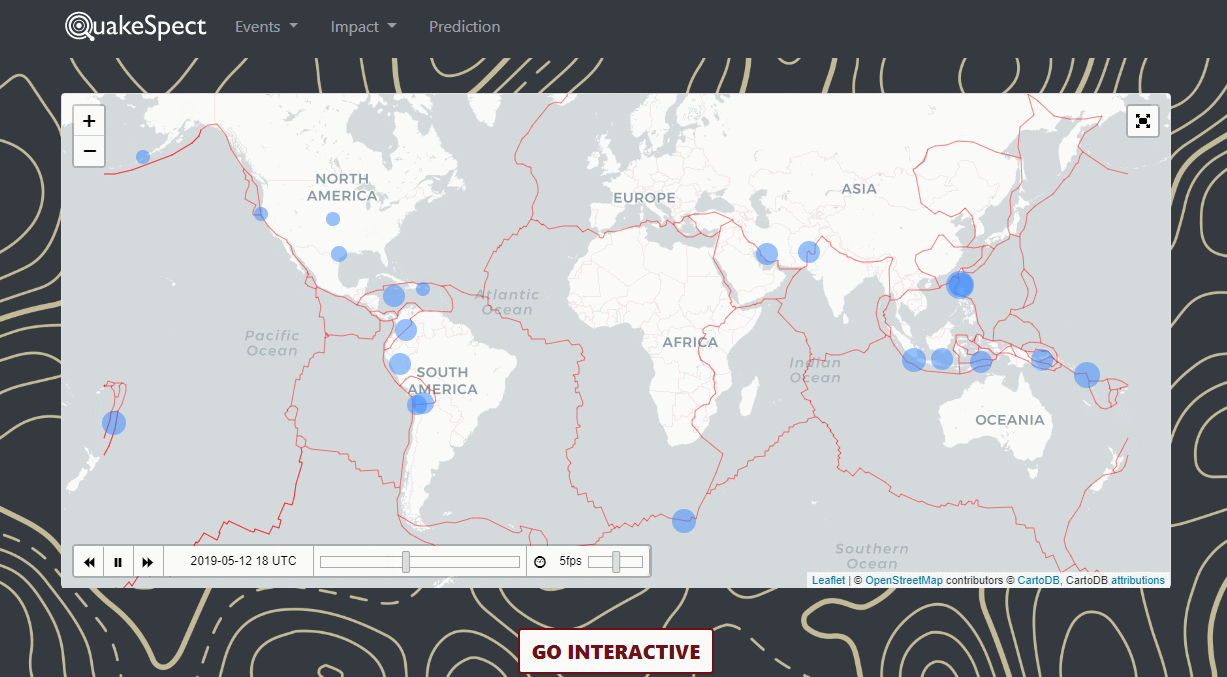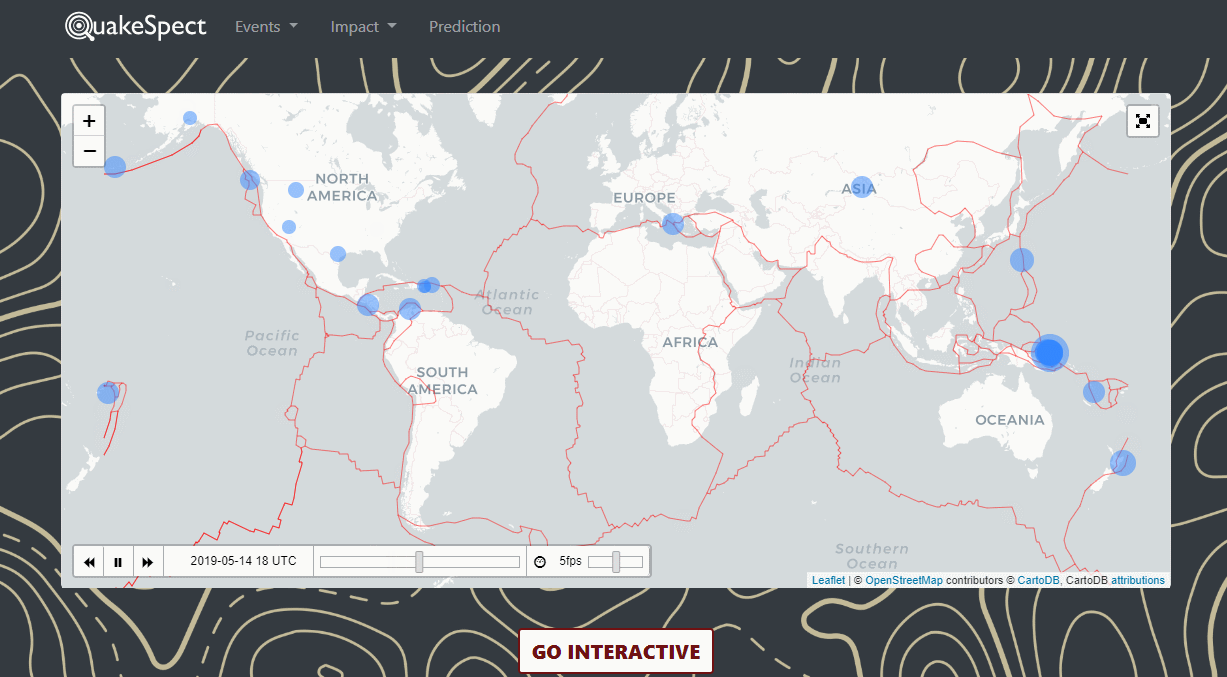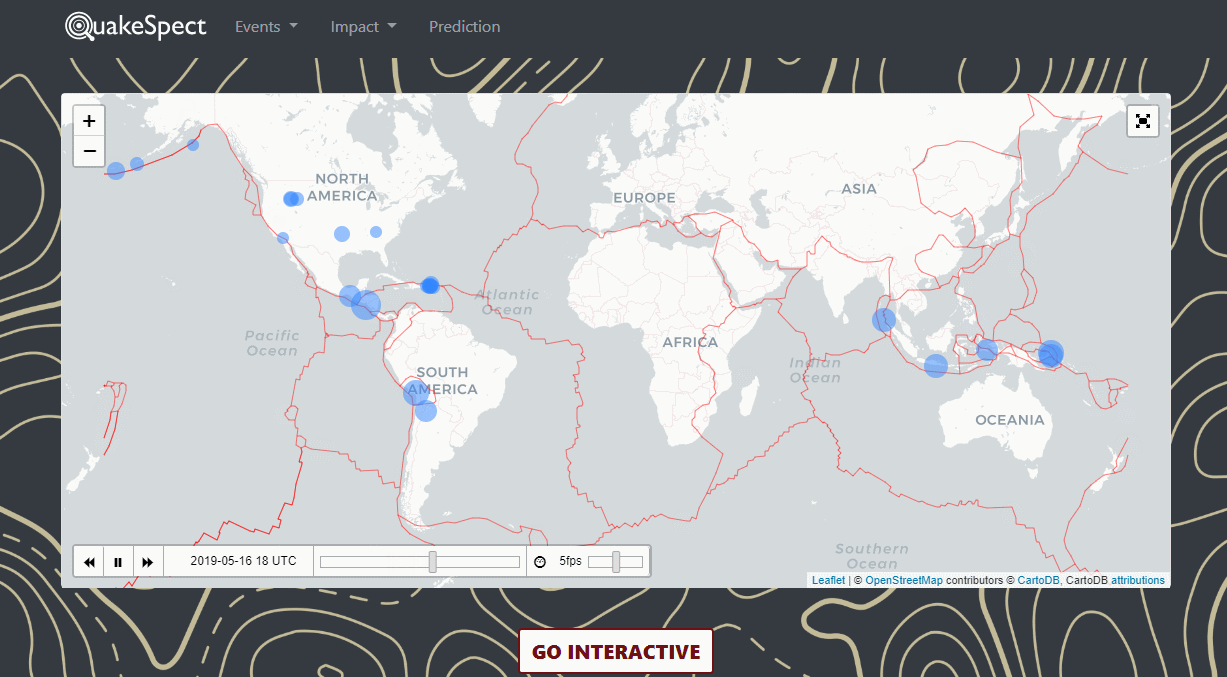
QuakeSpect is an overview of earthquake events, prediciton and impact. I built a live-streaming data visualization platform around USGS and implemented a baseline predictive model of future events.
View App View Code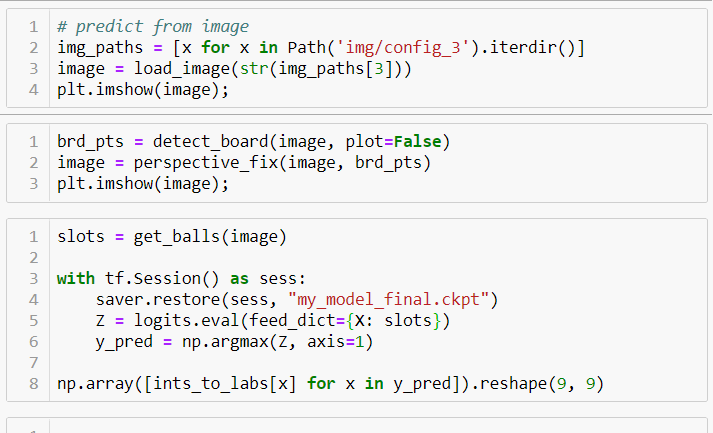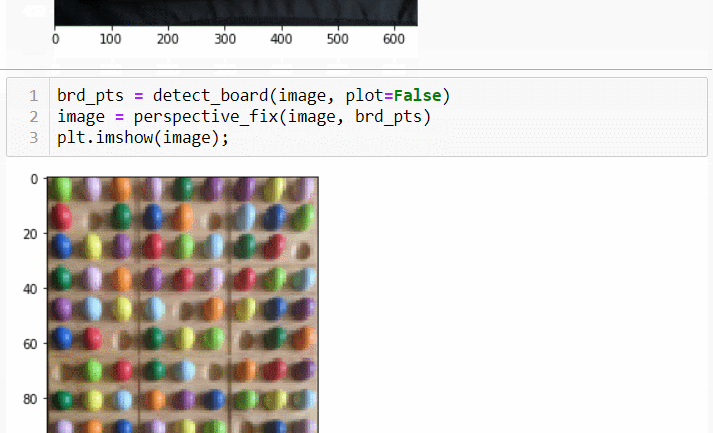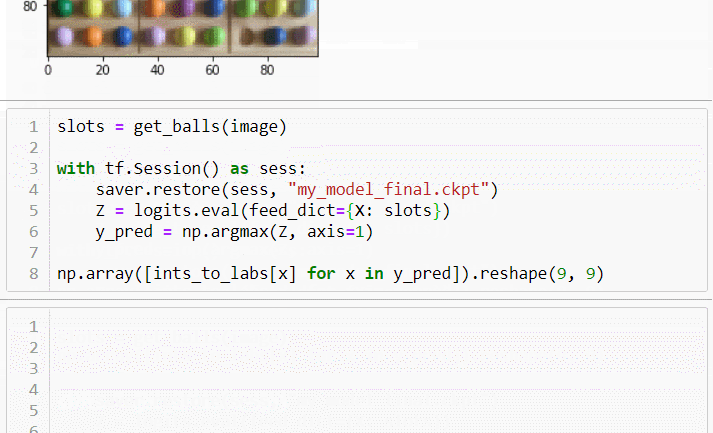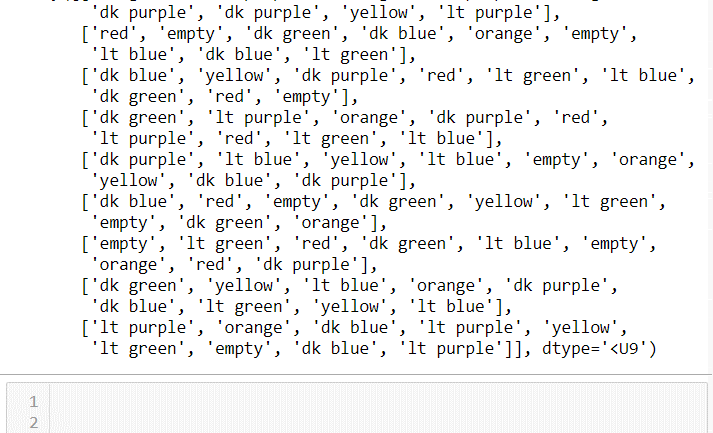
This computer vision deep neural network solves my sudoku boardgame in an instant with 99.5% accuracy. My next steps are to deploy to my Raspberry Pi and provide a user interface that coaches players toward the solution.
View Code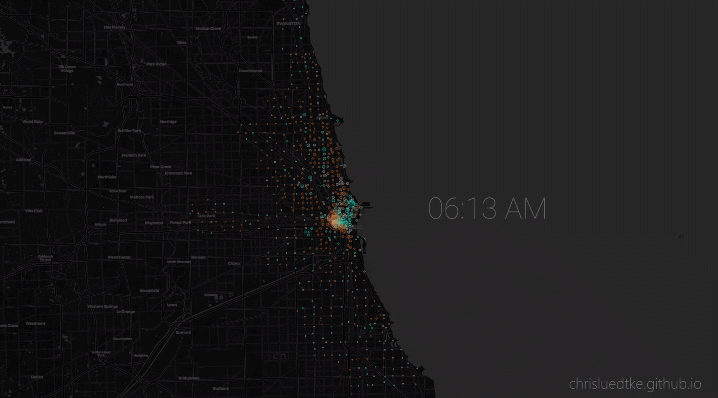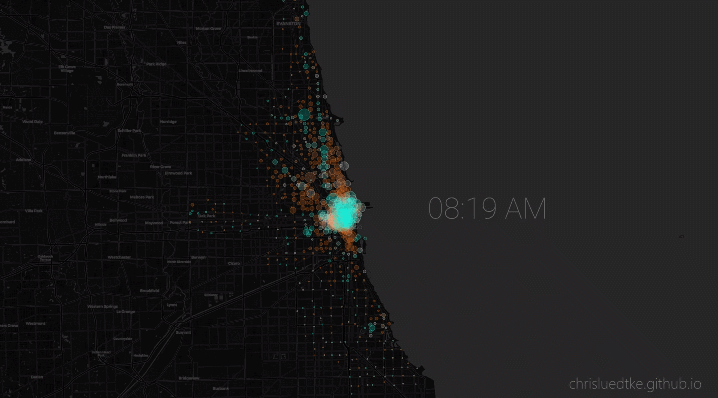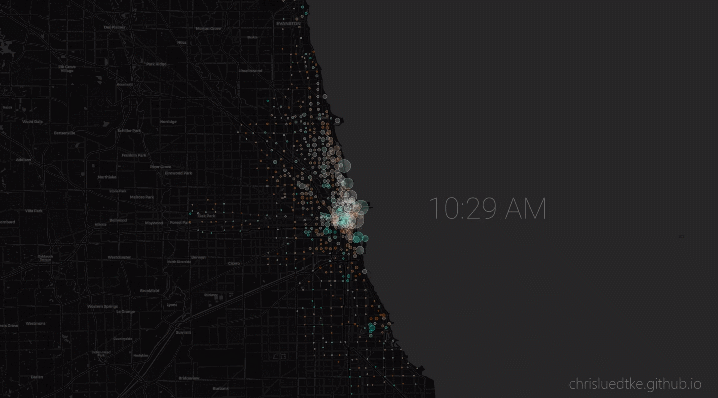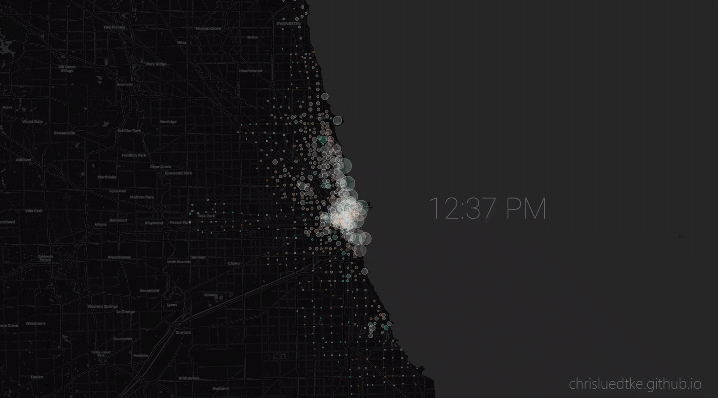
My python package allows users to conveniently download and monitor live and historic Chicago bikeshare data. I used this package to conduct my own analysis, culminating in an animation of the most representative 24 hours of bikeshare activity.
View Code Read More
I lead a team to implement simmulated annealing for greatly improved team placements. Using a Google API and user survey, we balanced team demographics and commute duration - an organizational first. This lead to 200% better commutes and an estimated $360,000 savings each year.
View Code Read MoreUsing live data from Chicago Transity Authority, I built a python application that maps train positions to LEDs for any section of track in the system, powered by a Rasberry Pi computer. Using GIS methods, I generated a scaled map of my neighborhood to perfectly fit the LED model. My next steps are to interpolate train positions for a smoother animation.

I co-founded and facilitate a monthly Algorithms & Data Structures meetup on behalf of Chicago Python Users Group. Participants select 1 of 3 code challenges and spend the evening honing their problem solving skills.
Join us every first Thursday of the month!
Read More
As a Chicago Python mentee in Spring 2018, I learned a massive amount and got a lot done. In addition to building a webapp to host a machine learning algorithm, I wrote a suite of tools for my AmeriCorps organization to automate data pipelines between Excel workbooks and Salesforce. This was largely accomplished with python’s Selenium and xlwings packages.
My three blog posts received “best of” designation, and I placed 3rd overall at the finale presentations. Find those materials at the link below.
Read More